
About me
Mingfu Liang is a Research Scientist at Meta AI. He obtained his Ph.D. at Northwestern University under the supervision of Professor Ying Wu. His research mainly revolves around machine learning and computer vision, with a special emphasis on the theoretical foundations and practical applications of these fields. His PhD thesis research is currently engrossed in enhancing machine learning algorithms with consistent, long-term learning capabilities and adaptive generalizability, enabling them to keep pace with a dynamic world. This research area, known as Continual Learning, Incremental Learning, and Lifelong Learning, aims to empower intelligent agents with a complete lifecycle. He earned his Master’s degree in Applied Math also from Northwestern University, where he specialized in analytical and computational methods for partial differential equations (PDE), stochastic differential equations (SDE), and advanced methods in parallel computing.
Apart from his thesis research of Continual Learning, his general research interests span various domains. He is actively involved in different research projects on Generative Models (e.g., GPT and Diffusion Models), Multi-modality Learning like Vision Question Answering (VQA) and Vision Language Models (VLM) and Large Multi-modality Models (LMM), Open World/Vocabulary Learning (e.g., Classification, Detection, and Segmentation), Model Customization and Personalization, Data-/Paremeter-Efficient Finetuning, Embodied AI and Robotic Learning, Domain Adaptation and Generalization, Autonomous Driving, Uncertainty Learning, Active/Few-shot/Semi-supervised Learning. All these research endeavors underline his commitment to furthering the field of machine learning and his goal to enable a new era of smart, adaptive machines.
Research before Ph.D. journey:
Before embarking on his Ph.D. journey, he actively tackled various intriguing challenges, including Image Matting, Semantic Segmentation, and Network Formulation. The latter encompassed areas like Network Pruning and Optimization, Attention Mechanism, Neural Architecture Search, and the Lottery Ticket Hypothesis. During his undergraduate studies in Pure and Applied Mathematics (specialized in Financial Mathematics and Engineering), he also displayed a keen interest in competitive problem-solving. He actively participated in numerous data mining and mathematical modeling competitions, securing noteworthy rankings and accolades in esteemed platforms such as the Mathematical Contest in Modeling (MCM), Kaggle, and the SIGKDD Cup.News
[2025.06] One paper on Geometry-Consistent Long-Horizon Scene Generation for Autonomous Driving is accepted by ICCV-2025!
[2025.05] One paper on RAG-Enhanced LLM is accepted by the ACL-2025 main conference!
[2025.02] Two papers about Incremental Object Keypoint Learning and Efficient Vision Language Model are accepted by CVPR-2025!
[2025.01] Two papers about Multi-modality Recommendation Systems and External Large Foundation Model (ExFM) have been accepted by WWW-2025! ExFM is accepted as Oral on WWW-2025 Industrial Track!
[2025.01] One paper about Flat Local Minima for Continual Learning has been accepted as Best Paper Nomination in International Conference on Multimedia Modeling (MMM)!
[2025.01] Joined Meta AI as a Research Scientist!
[2024.12] Obtained my Ph.D. from Northwestern University! Thank everyone for supporting me during this journey!
[2024.06] Joined Meta AI as a Research Scientist Intern!
[2024.06] Attending CVPR-2024 in Seattle from June 16 to 21st to present AIDE at the main conference and two workshops. Feel free to contact me if you want to chat about the large multi-modality Model (LMM), continual learning, model scaling, data curation, and autonomous driving!
[2024.04] Joined the Privacy-Preserving Machine Learning (PPML) team at Sony AI this Spring (April - June) as a Research Intern, working on Scalable and Versatile Multi-Modality (Vision-Language) Foundation Models!
[2024.02] Two papers have been accepted by CVPR-2024, “AIDE: An Automatic Data Engine for Object Detection in Autonomous Driving” and “Evidential Active Recognition: Intelligent and Prudent Open-World Embodied Perception”! AIDE has further been accepted as the poster presentation at CVPR-2024 Workshop of Data-Driven Autonomous Driving Simulation (DDADS) and as Oral presentation at CVPR-2024 Workshop of Vision and Language for Autonomous Driving and Robotics (VLADR)! Thanks to all my mentors and collaborators from NEC Labs and Northwestern University! See you in Seattle this Summer!
[2024.01] Joined Department of Media Analytics at NEC Lab America this Winter quarter (January - March) again as a research intern on Controllable Video/Image Generation Models for Autonomous Driving!
[2023.09] The paper “TOA: Task-oriented Active VQA” is accepted by NeurIPS-2023! See you in New Orleans this December!
[2023.07] The paper “Understanding Self-attention Mechanism via Dynamical System Perspective” is accepted by ICCV-2023. More details are coming soon!
[2023.06] An interesting course final project with Bin Wang on Virtual Try-on based on Segment Anything model and Conditional Generative models (Stable Diffusion and Conditional GANs) training by the Diffuser repo from Huggingface! Some code snippets are released here
[2023.04] I will be interning in the Department of Media Analytics at NEC Lab America this summer on Autonomous Driving and Continual Learning, working with Dr. Jong-Chyi Su, Dr. Samuel Schulter, and Prof. Manmohan Chandraker.
[2022.12] Gave a talk for the Incremental Subpopulation Shifting (ECCV-2022) at AI TIME.
[2022.07] The paper “Balancing between Forgetting and Acquisition in Incremental Subpopulation Learning” is accepted by ECCV-2022! The code is released here.
[2022.06] Start my internship in the Department of Machine Learning at NEC Lab America on Interactive Visual Exploration System, working with Dr. Erik Kruus.
[2020.09] Start my Ph.D. journey at Northwestern University!
Selected Publications (*: contributed equally)
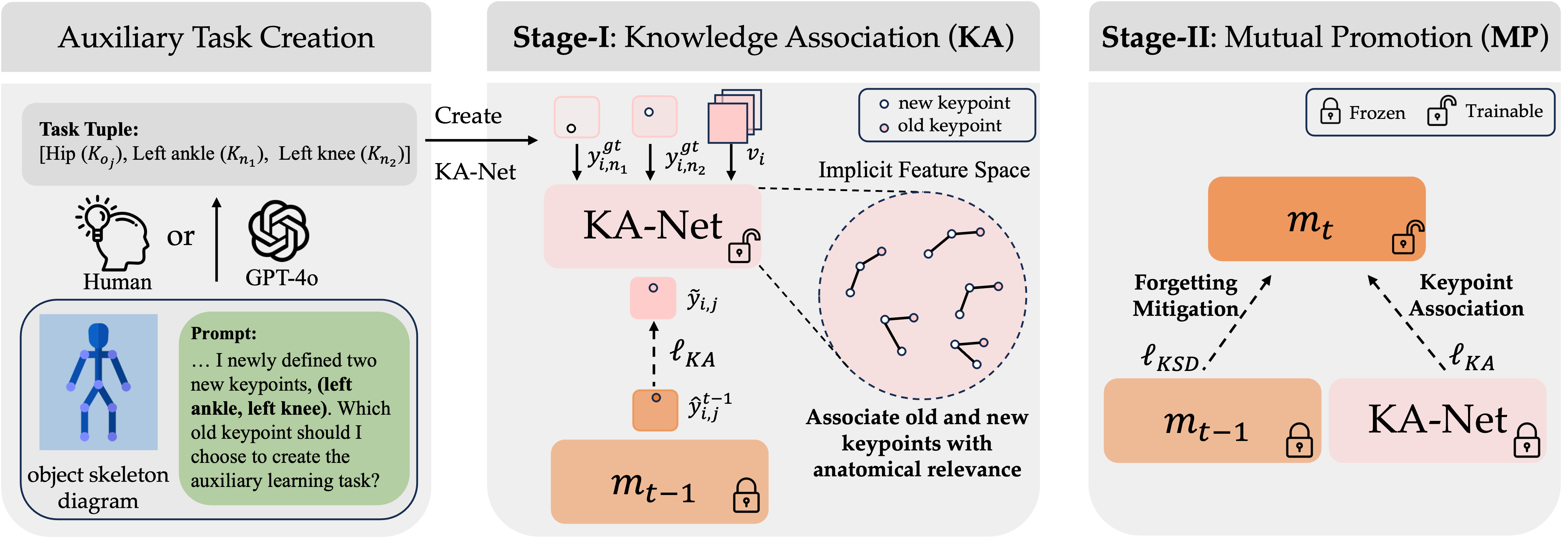
Incremental Object Keypoint Learning
CVPR 2025
[ArXiv]
Main Takeaways:
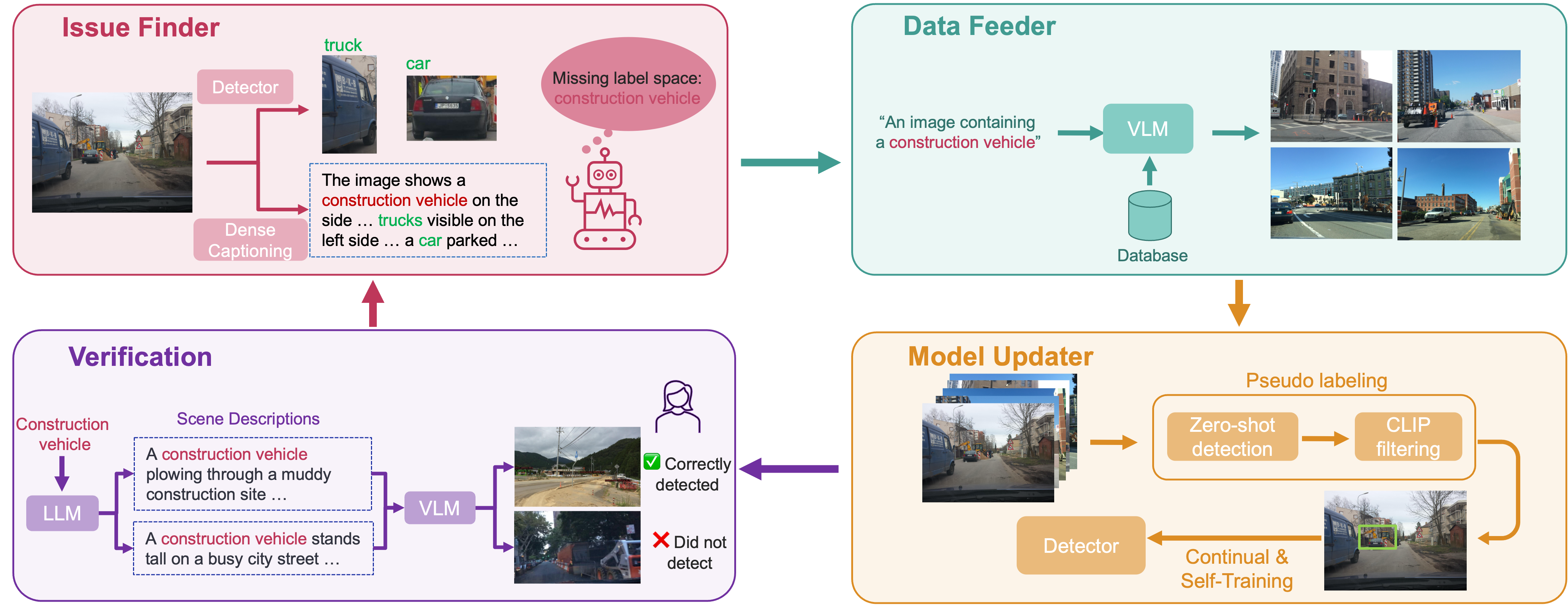
AIDE: An Automatic Data Engine for Object Detection in Autonomous Driving
CVPR 2024
Vision and Language for Autonomous Driving and Robotics (VLADR) Workshop, CVPR 2024 (Oral)
Data-Driven Autonomous Driving Simulation (DDADS) Workshop, CVPR 2024
[ArXiv] [Poster] [YouTube] [Proceeding] [LinkedIn Post]
Main Takeaways:
• AIDE composites of automatic issue identification, efficient data curation, model improvement via auto-labeling, and verification through diverse AV scenarios generation, all intelligently powered by recent advancements on VLMs and LLMs .
• AIDE can automatically enable closed-set object detectors to detect novel objects, outperforming state-of-the-art (SOTA) open-vocabulary object detectors (OVOD) with a large margin; Achieved the highest cost-efficiency (training and/or labeling) than learning paradigms like fully, semi-supervised, and active learning. AIDE can also maintain and even improve the performance on known-object detection and improve SOTA OVOD by >4% average precision (AP) on novel categories without human labels.
• Iterative use of AIDE significantly boosts performance, and minimal human feedback can lead to substantial gains, e.g., an extra 5.5% AP increased by correcting 30 images in the Verification of AIDE. Last but not least, AIDE can also scale up with more unlabeled data and approach the fully-supervised upper bound.
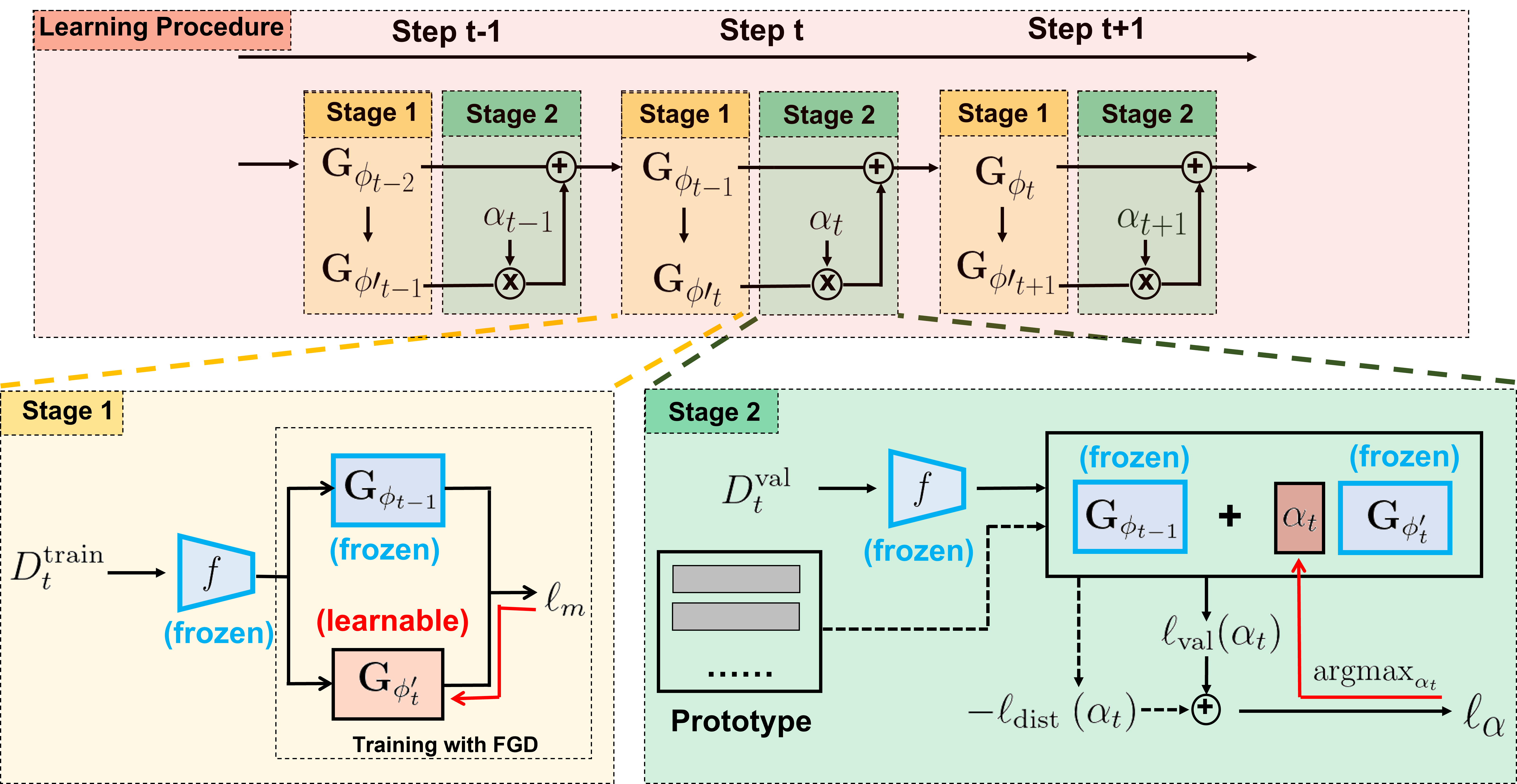
Balancing between Forgetting and Acquisition in Incremental Subpopulation Learning
ECCV 2022
[Twitter] [Poster] [PDF] [Supp.] [Springer] [Code] [YouTube] [Project Page]
Main Takeaways:
• Empirically shown that ISL is promising for alleviating the subpopulation shifting problem (i.e., the large performance drop, mostly >30%, when a model directly tests on unseen subpopulations), without sacrificing the original performance on the seen population.
• Proposed a two-stage learning framework as a novel and the first baseline tailored to ISL , which disentangles the knowledge acquisition and forgetting to better handle the stability and plasticity trade-off inspired by the generalized Boosting Theory. Proposed novel proxy estimations to measure the forgetting and knowledge acquisition approximately to create a new optimization objective function for ISL.
• Benchmark the representative and the state-of-the-art (SOTA) non-exemplar-based methods on a recently proposed large-scale dataset tailored to real-world subpopulation shifting for the first time, i.e., the BREEDS datasets. Conducted extensive empirical study and formal analysis for the proposed and comparison methods to enlighten future research directions.
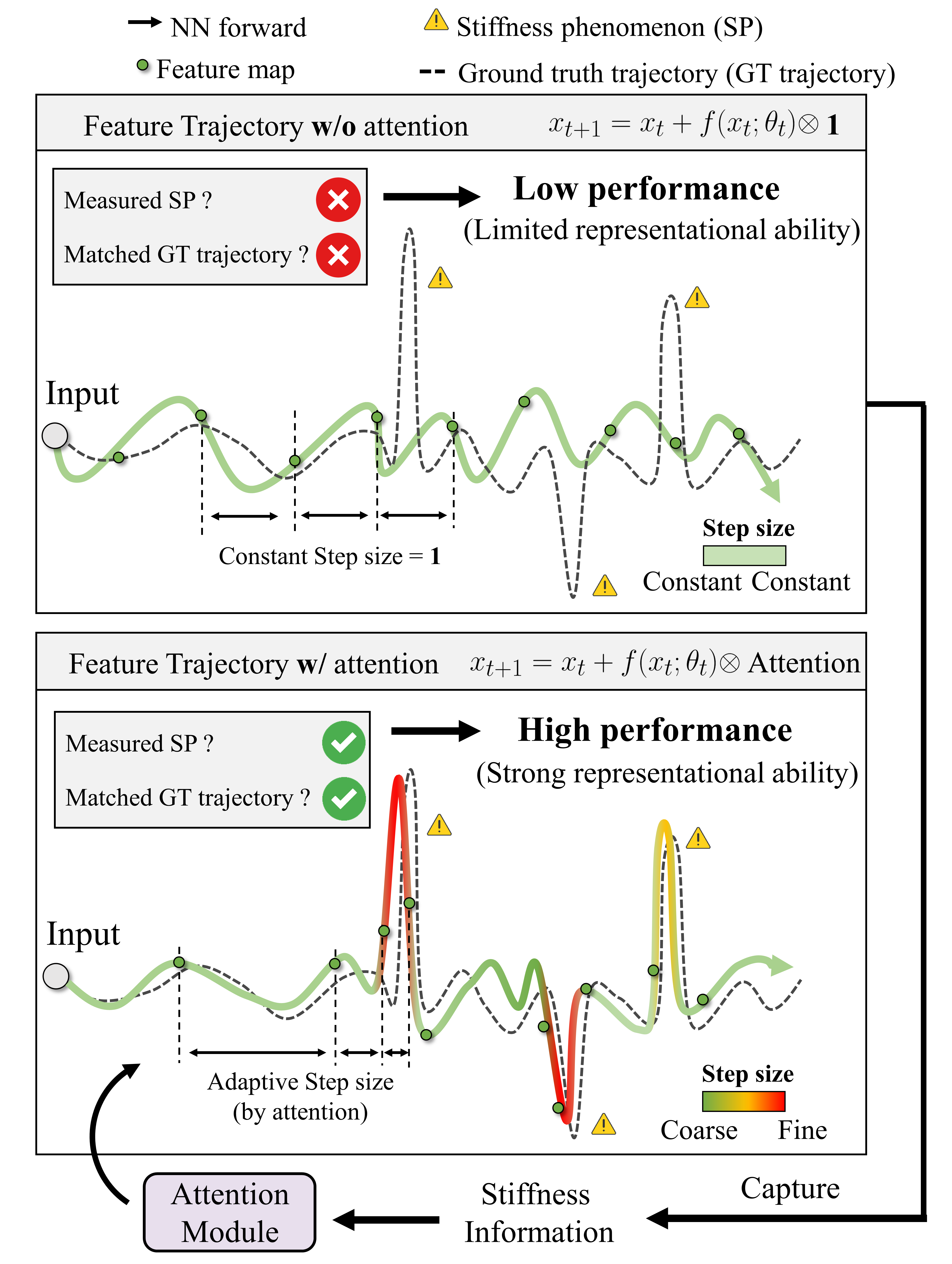
Understanding Self-attention Mechanism via Dynamical System Perspective
ICCV 2023
[ArXiv][Media Cover (in Chinese)]
Main Takeaways:
• We formally demonstrate that the Self-Attention Mechanism (SAM) is a stiffness-aware step size adaptor that can enhance the model's representational ability to measure intrinsic SP by refining the estimation of stiffness information and generating adaptive attention values, which provides a new understanding of why and how the SAM can benefit the model performance
• This novel perspective can also explain the lottery ticket hypothesis in SAM, design new quantitative metrics of representational ability, and inspire a new theoretic-inspired approach, StepNet.
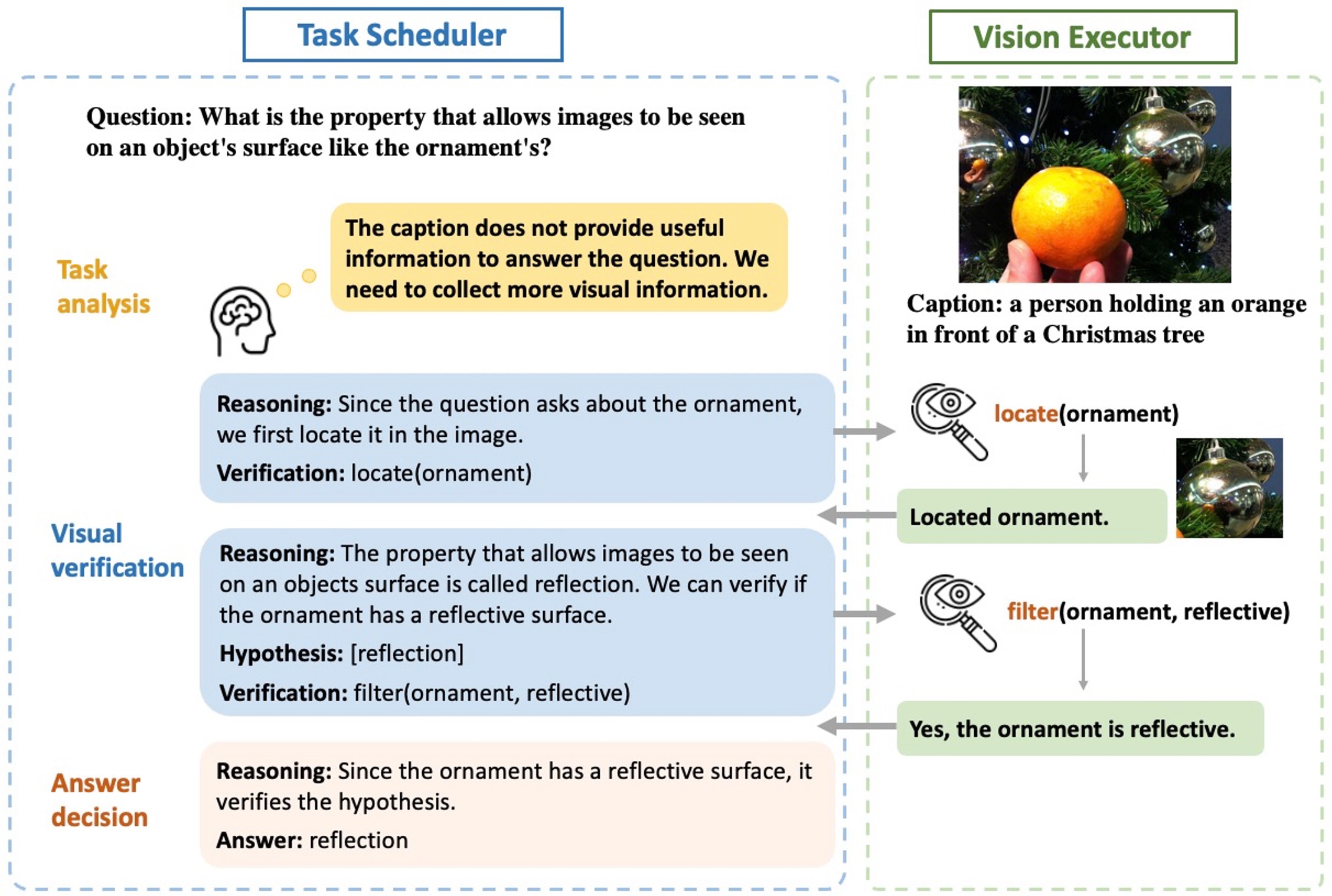
TOA: Task-oriented Active VQA
NeurIPS 2023
[OpenReview]
Main Takeaways:
• TOA consists of a LLM as the scheduler to recurrently make dynamic task planning and decision like the human, and a visual executor to execute the order from the scheduler. The LLM in our TOA interacts with the vision modality progressively through multi-round dialogue to dynamically generate the task-oriented planning based on the previous interaction experience.
• The LLM analyze the question and the initial caption returned by the vision executor, and then either make hypothesis or require for more information based on the initial understanding of the input question obtained by its captioning and the open-world knowledge obtained during LLM pretraining.
• The LLM then dynamically adjust its hypothesis based on previous conversations and the visual evidence obtained by the vision executor. Such a hypothesis-reasoning-verification procedure occurs repeatedly to let the LLM activate its internal open-world knowledge by making hypothesis and reasoning, and proactively engage with the image to gather relevant information.
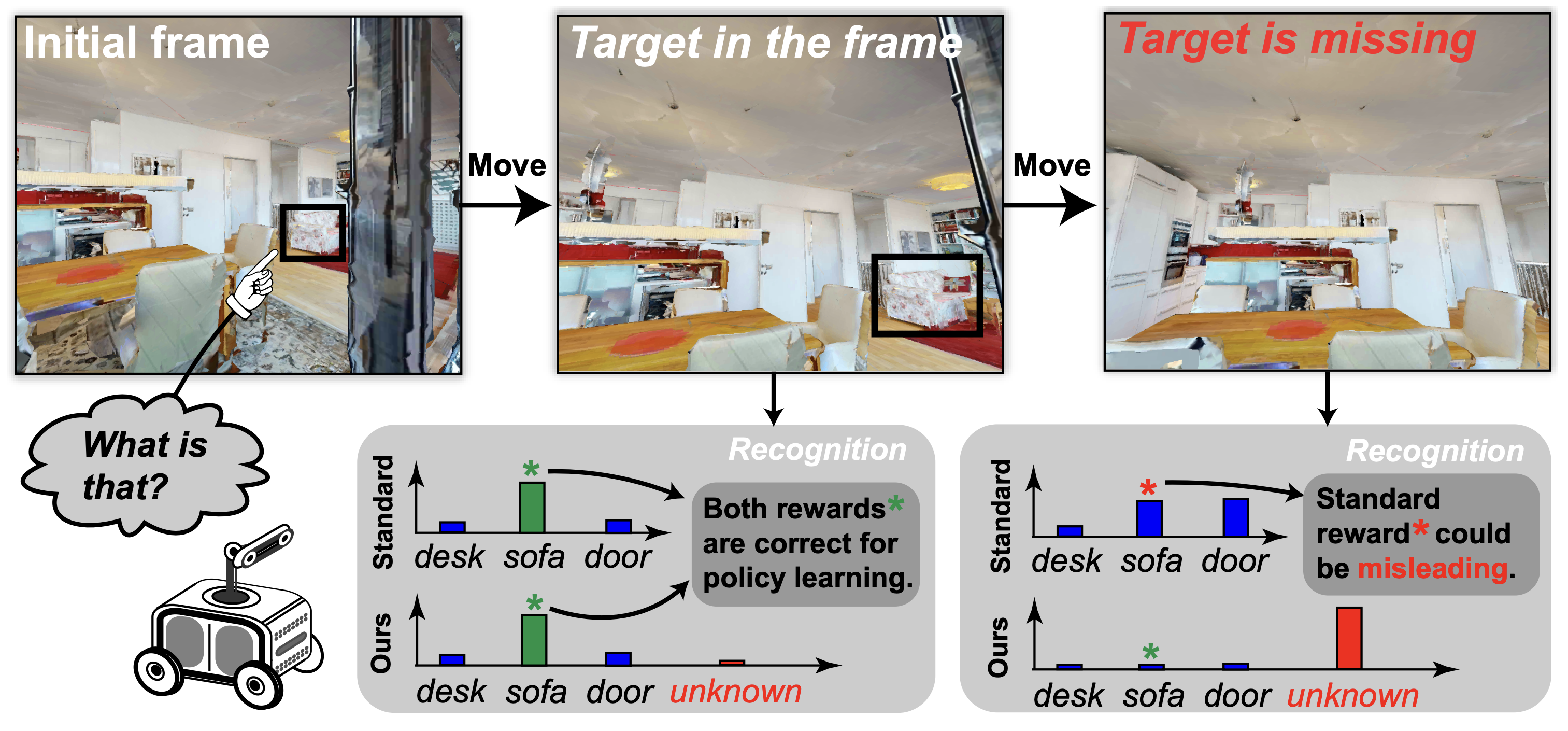
Evidential Active Recognition: Intelligent and Prudent Open-World Embodied Perception
CVPR 2024
[ArXiv]
Main Takeaways:
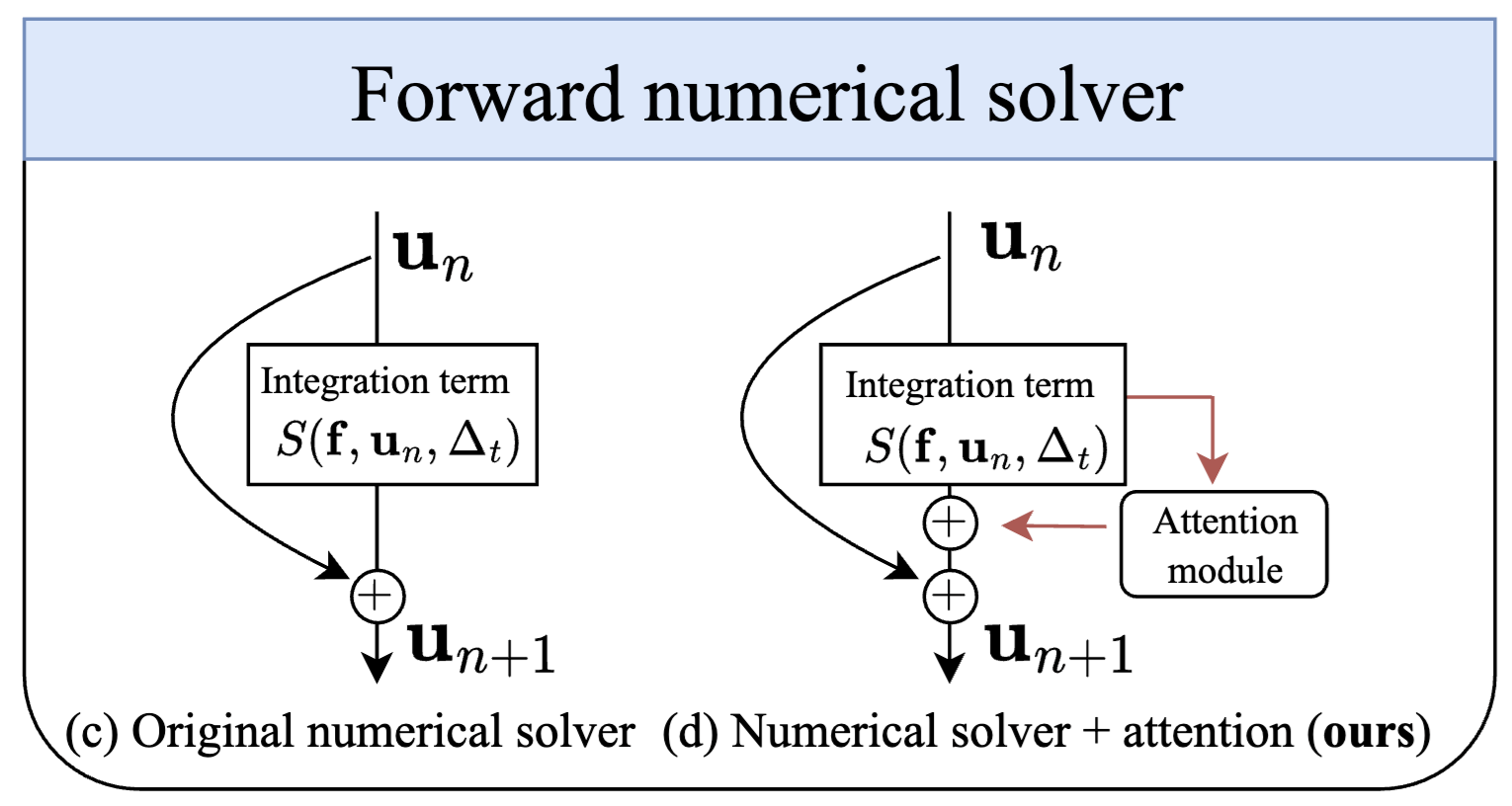
AttNS: Attention-Inspired Numerical Solving For Limited Data Scenarios
ICML 2024
Main Takeaways:
Other Publications (*: contributed equally)

Exploring Compositional Visual Generation with Latent Classifier Guidance
CVPR 2023, Workshop of Generative Models for Computer Vision
[ArXiv]
Main Takeaways:
Lecture I gave about "Guidance for Diffusion Model" on CS-496 Deep Generative Models, Slides
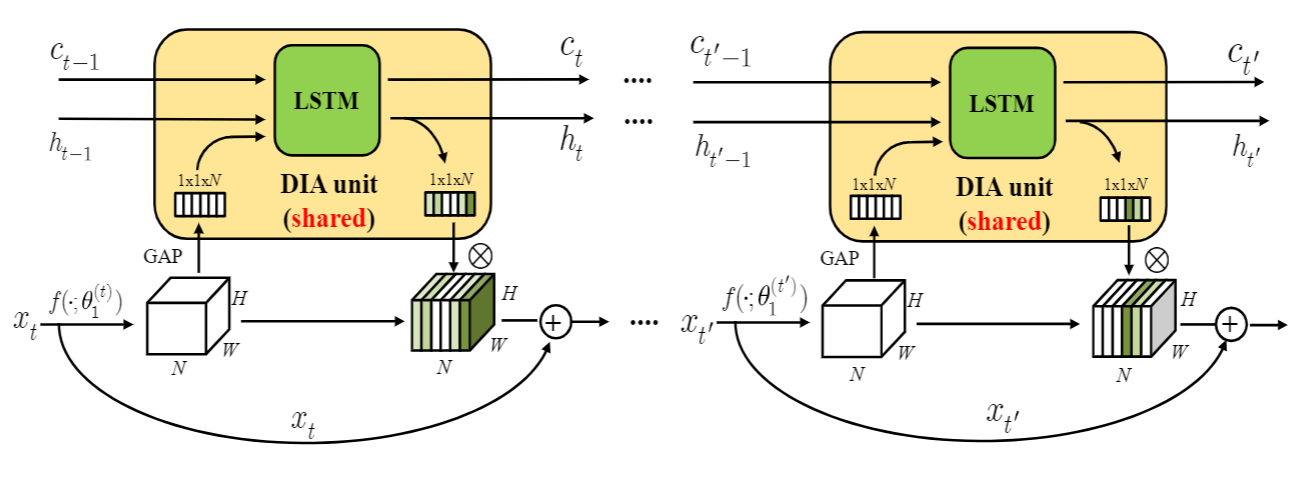
DIANet: Dense-and-Implicit Attention Network
AAAI 2020
[PDF] [Code]
Main Takeaways:
• Many choices of modules can be used in the DIA unit. Since Long Short Term Memory (LSTM) has the capacity to capture long-distance dependency, we focus on the case when the DIA unit is the modified LSTM (called DIA-LSTM).
• Experiments on benchmark datasets show that the DIA-LSTM unit is capable of emphasizing layer-wise feature interrelation and leads to significant improvement in image classification accuracy.
• We further empirically show that the DIA-LSTM has a strong regularization ability on stabilizing the training of deep networks by the experiments with the removal of skip connections (He et al. 2016a) or Batch Normalization (Ioffe and Szegedy 2015) in the whole residual network.
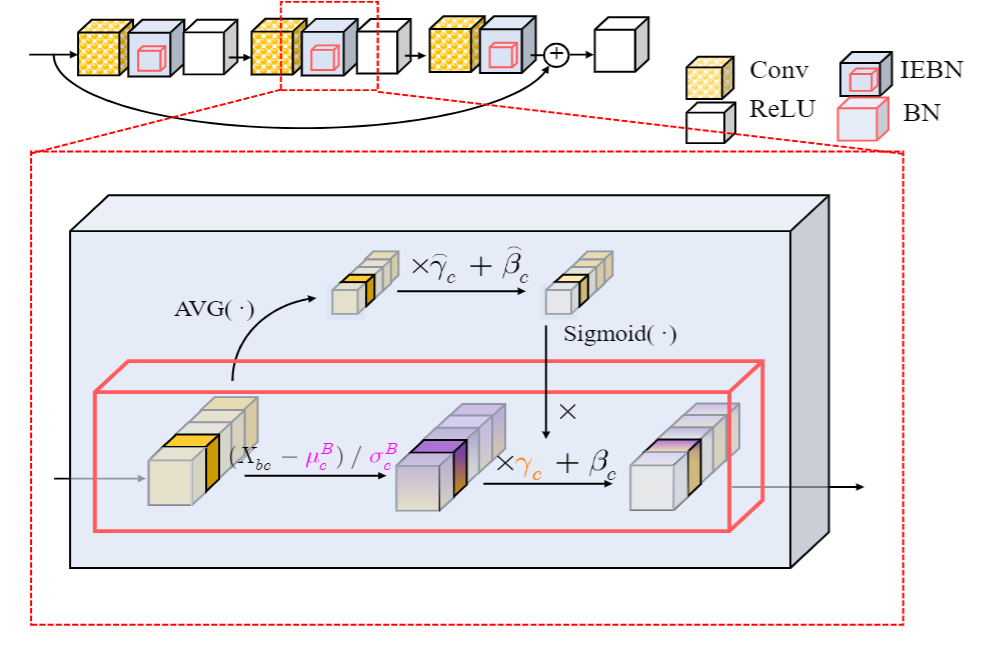
Instance Enhancement Batch Normalization: An Adaptive Regulator of Batch Noise
AAAI 2020
[PDF] [Code]
Main Takeaways:
• We propose an attention-based BN called Instance Enhancement Batch Normalization (IEBN) that recalibrates the information of each channel by a simple linear transformation.
• IEBN has a good capacity for regulating the batch noise and stabilizing network training to improve generalization even in the presence of two kinds of noise attacks during training.
.png)
CAP: Context-Aware Pruning for Semantic Segmentation
WACV 2021
[PDF] [Code] [Supplementary] [Video]
Main Takeaways:
• The first work to explore contextual information for guiding channel pruning tailored to semantic segmentation.
• We formulate the embedded contextual information by leveraging the layer-wise channels interdependency via the Context-aware Guiding Module (CAGM) and introduce the Context-aware Guided Sparsification (CAGS) to adaptively identify the informative channels on the cumbersome model by inducing channel-wise sparsity on the scaling factors in batch normalization (BN) layers.
• The resulting pruned models require significantly fewer operations for inference while maintaining comparable performance to (at times outperforming) the original models. We evaluated our framework on widely used benchmarks and showed its effectiveness on both large and lightweight models.
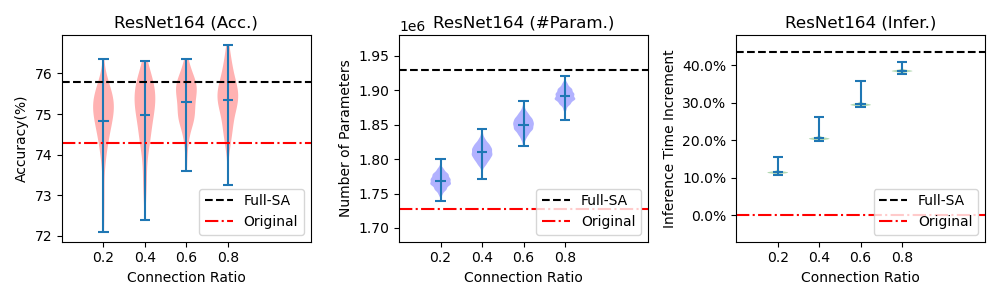
Lottery Ticket Hypothesis for Attention Mechanism in Residual Convolutional Neural Network
ICME 2024 (Oral)
Main Takeaways:
Academic Service
- Invited Conference Reviewer/Program Committee Member:
- British Machine Vision Conference (BMVC): 2020
- AAAI Conference on Artificial Intelligence (AAAI): 2021, 2022, 2023, 2024, 2025
- IEEE/CVF Winter Conference on Applications of Computer Vision (WACV): 2021
- Asian Conference on Computer Vision (ACCV): 2024
- Conference on Computer Vision and Pattern Recognition (CVPR): 2021, 2022, 2023, 2024, 2025
- International Conference on Computer Vision (ICCV): 2021, 2023, 2025
- European Conference on Computer Vision (ECCV): 2022, 2024
- Conference on Lifelong Learning Agents (CoLLAs): 2023, 2024, 2025
- IEEE International Conference on Multimedia and Expo (ICME): 2023
- Conference on Neural Information Processing Systems (NeurIPS): 2023, 2024, 2025
- International Conference on Learning Representations (ICLR): 2024, 2025
- International Conference on Machine Learning (ICML): 2024, 2025
- Conference on Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track: 2024
- International World Wide Web Conference (WWW): 2025
- International World Wide Web Conference (WWW) Companion: 2025
- Invited Journal Reviewer:
- IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)
- IEEE Transactions on Neural Networks and Learning Systems (TNNLS)
- IEEE Transactions on Multimedia (TMM)
- International Journal of Computer Vision (IJCV)
- Pattern Recognition Letters (PRL)
- Machine Vision and Applications (MVA)
- ACM Computing Surveys (CSUR)
- IEEE Transactions on Intelligent Systems and Technology (TIST)
- IEEE Transactions on Circuits and Systems for Video Technology (TCSVT)